
Products
-
-
- Accessories
- Breakout boards
This page has deprecated and moved to the new documentation framework of the main Bitcraze website. Please go to https://www.bitcraze.io/documentation/system/ or https://www.bitcraze.io/documentation/repository/
Adds the possibility to read and write files to a micro SD card.
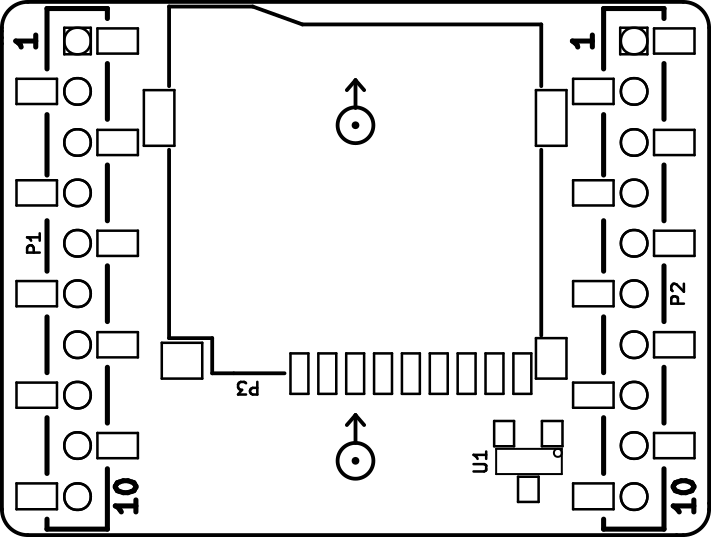
micro-SD expansion deck schematic
We use FatFS as the file system handler. Have a look at the API and examples on the FatFS site fore usage information.
The FatFS module will be initialized by the micro-SD deck driver when the deck is detected. After that the API calls can be used such as f_mount, f_open, f_read, f_close etc.
Without any changes to usddeck.c there's a data logging functionality implemented. It can be enabled and configured by placing a config file on the µSD-Card. The file is a simple text file and an example is available (config.txt). The file format is as follows:
Frequency Number of buffers File name log entry 1 log entry 2 log entry 3 ...
Frequency is an integer value in Hertz, for example 250 means that a data block is written every 4ms. The number of buffers is used to decouple the writing to the card and the data logging. Higher frequencies require more buffers, otherwise some data might be lost. Logging 10dof data with 1kHz works well with a buffer of 120 elements. But you may have to try around a bit to get feeling on what is possible. If the buffer was too small or the frequency was too high there will be gaps in the log as you can see in the following picture:

The file name should be 10 characters or less and a running number is appended automatically (e.g., if the file name is log, there will be files log00, log01, log02 etc.). The log entries are the names of logging variables in the firmware.
The config.txt file will be read only once on startup, therefore make sure that the µSD-Card is inserted before power up. If everything seems to be fine a µSD-task will be created and buffer space will be allocated. If malloc fails crazyflie will stuck with LED M1 and M4 glowing, otherwise data logging starts automatically after sensor calibration. The logfiles will be enumerated in ascending order from 00-99 to allow multiple logs without the need of creating new config files. Just reset the crazyflie to start a new file. For performance reasons the logfile is a binary file, but the python module also contains a function which will return the data as dictionary. For decoding just call
import CF_functions as cff logData = cff.decode(fileName)
where fileName is a file from the µSD-Card. For convenience there is also an example.py which shows how to access and plot the data.
The SD-Card is using the SPI bus on the deck port to communicate. This has turned out to have some implications for the other decks that use the SPI bus. The effected decks are the Loco-deck and the Flow v1,v2 deck. An issue has been open about it and this has finally been solved but there might still be interesting to use the other SPI bus sometimes. One workaround is to use a “hidden” SPI on the deck port that is multiplexed with TX1, RX1 and IO_4. This SPI port is called SPI3 in the STM32F405 and after this commit there is a possibility to switch to this SPI bus.
